新年第一天, DeepSeek 發布了一篇新論文,提出了一個名為 mHC (流形約束超連結)的新架構。該研究旨在解決傳統超連接在大規模模型訓練中的不穩定性問題,同時保持其顯著的效能增益。
簡單來說,DeepSeek 提出的mHC 透過將傳統Transformer 的單一殘差流擴展為多流並行架構,並利用Sinkhorn-Knopp 演算法將連接矩陣約束在雙擬隨機矩陣流形上,成功解決了超連接(HC)在大規模訓練中因破壞等映射屬性而導致的數值不穩定和訊號爆炸問題。

這篇論文的第一作者有三位:Zhenda Xie(解振達)、Yixuan Wei(韋毅軒)、Huanqi Cao。值得注意的是,DeepSeek 創辦人& CEO 梁文鋒也在作者名單中。
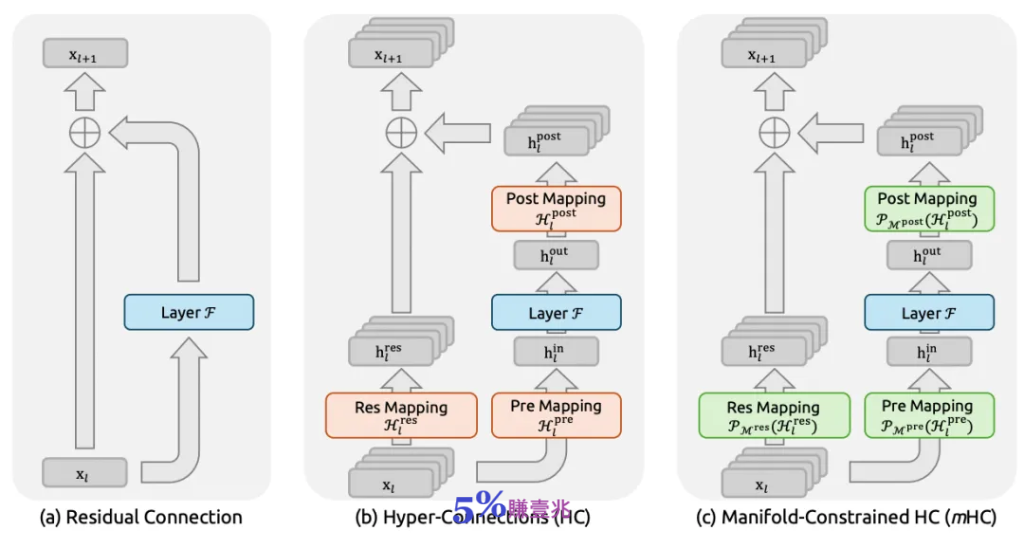
傳統的殘差連接(即Transformer 中的x + F (x) 結構)憑藉「恆等映射」保證了訊號無損傳輸和訓練穩定性。但它的瓶頸在於資訊通道的寬度受限於隱藏層維度C。
近期,以Hyper-Connections (HC) 為代表的研究,透過擴展殘差流寬度和多樣化連接模式,拓展了過去十年廣泛應用的殘差連結範式。
雖然這些方法帶來了顯著的效能提升,但也帶來了兩個嚴重問題:
從根本上破壞了殘差連接固有的恆等映射屬性,導致了嚴重的訓練不穩定性和受限的可擴展性,並額外增加了顯著的記憶體存取開銷。
為了解決這些挑戰,DeepSeek 的研究團隊提出了 Manifold-Constrained Hyper-Connections (mHC,流形約束超連接)。
這是一個通用框架,它將HC 的殘差連接空間投影到一個特定的流形上,以恢復恆等映射屬性,同時結合嚴格的基礎設施最佳化以確保效率。
它的核心目的是:在保留「加寬殘差流」所帶來的效能提升的同時,解決其導致的訓練不穩定和顯存消耗過大的問題。
團隊利用 Sinkhorn-Knopp 演算法將殘差連接矩陣投影到Birkhoff 多胞形(雙隨機矩陣)上。這使得訊號傳播變為特徵的「凸組合」,從數學上嚴格保證了訊號範數的穩定性(能量守恆)。為了抵消加寬通道帶來的開銷,團隊實施了內核融合、選擇性重計算以及擴展的DualPipe 通訊計算重疊策略。
實證表明,mHC 不僅解決了穩定性問題,且在大規模訓練中(如27B 模型)表現出卓越的可擴展性。在n=4 的擴展倍率下,僅增加了6.7% 的訓練時間開銷,卻換來了顯著的效能提升。 mHC 為基礎模型的拓樸架構演進指明了方向。
圖1:殘差連結範式示意圖。 本圖比較了以下三種結構設計: (a) 標準殘差連結(Residual Connection); (b) Hyper-Connections (HC); (c) 我們提出的Manifold-Constrained Hyper-Connections (mHC)。與無約束的HC 不同,mHC 專注於優化殘差連接空間,透過將矩陣投影到受約束的流形上,以確保穩定性。
具體方法介紹
流形約束超連接(mHC)
借鑒恆等映射(Identity Mapping)原則,mHC 的核心前提是將殘差映射Hlres約束在一個特定的流形上。
雖然原始的恆等映射是透過強制執行Hlres=1來確保穩定性,但它能從根本上阻止殘差流內部的資訊交換,而這種交換對於最大化多流架構的潛力至關重要。
因此,此DeepSeek 團隊提出將殘差映射投影到一個流形上,既能保持跨層訊號傳播的穩定性,又能促進殘差流之間的相互作用,以維持模型的表達能力(expressivity)。
為此,他們的做法是將Hlres限制為雙擬隨機矩陣(Doubly Stochastic Matrix),即具有非負項且行和與列和均為1 的矩陣。
形式上,令Mres表示雙擬隨機矩陣的流形(也稱為Birkhoff 多胞形),再將Hlres約束在PMres (Hlres)中,定義為:

其中1_n 表示全1 的n 維向量。
為什麼選擇雙擬隨機性?因為其具有多項有利於大規模訓練的理論屬性:

此外,該團隊還對輸入映射 Hlpre 和輸出映射Hlpost施加了非負約束,以防止因正負係數複合而導致的訊號抵消。
參數化與流形投影
本節將詳述mHC 中各映射的計算過程。
給定第l 層的輸入隱藏矩陣x_l,先將其展平為向量

以保留完整的上下文資訊。然後,按照HC 的原始公式取得動態映射和靜態映射:
最終的約束映射透過以下方式獲得:
其中  是Sigmoid函數。 Sinkhorn-Knopp 算子首先透過指數操作確保所有元素為正,然後進行迭代規範化,交替縮放行和列使其和為1。
是Sigmoid函數。 Sinkhorn-Knopp 算子首先透過指數操作確保所有元素為正,然後進行迭代規範化,交替縮放行和列使其和為1。
DeepSeek 在實驗中採用t_max=20 次迭代。
高效基礎設施設計
DeepSeek 還為mHC 量身定制了基礎設施設計,使其在n=4 時在大模型中的訓練開銷僅增加6.7%:
算子融合(Kernel Fusion):
重新調整RMSNorm 的順序以提高效率,並採用混合精度策略。
開發了統一的算子,將多次掃描和矩陣乘法融合,減少記憶體頻寬瓶頸和算子啟動開銷。
在單一算子中實現Sinkhorn-Knopp 迭代及其自訂反向傳播。將 Hlpost和 Hlpre的應用與殘差合併融合,顯著減少了記憶體讀寫量
重新計算(Recomputing):
為了減輕n 流設計帶來的記憶體壓力,DeepSeek 在前向傳播後丟棄mHC 算子的中間激活,並在反向傳播時即時重新計算。
透過推導得出最優重計算區塊大小L_r^*,以最小化總記憶體佔用。
DualPipe 中的通訊重疊:
擴展了DualPipe 調度演算法,以改善管線並行階段邊界處的通訊與計算重疊在專用高優先權計算流上執行MLP 層的內核,並避免在註意力層使用持久算子,以防止阻塞通訊流並提高設備利用率。
實驗
實驗設定
研究團隊透過語言模型預訓練來驗證所提方法的有效性,並對基線模型、超連接(HC)以及提出的流形約束超連接(mHC)進行了對比分析。
他們採用了受DeepSeek-V3 啟發的MoE 架構,訓練了四種不同的模型變體,以涵蓋不同的評估系統。
具體而言,HC 和mHC 的擴展率n 均設定為4,主要關注點是一個27B 參數規模的模型。其訓練資料集的大小與其參數量成正比,該模型用於展示系統層面的主要結果。在此基礎上,他們透過引入使用成比例資料訓練的較小的 3B 和9B 模型來分析計算擴展性,從而觀察不同計算規模下的效能趨勢。此外,為了專門研究Token 規模的影響,他們另外訓練了一個獨立的3B 模型,該模型在一個固定的1T Token 的語料庫上進行訓練。

主要結果
圖5:流形約束超連結(mHC) 的訓練穩定性。 此圖展示了:(a) mHC 和HC 相對於基線模型的訓練損失絕對差異;(b) 三種方法在訓練過程中的梯度範數。所有實驗均基於27B 參數規模的模型。實驗結果表明,mHC 在損失函數和梯度範數兩方面均表現出更優的穩定性。
研究團隊首先檢視27B 模型的訓練穩定性和收斂性。如圖5 (a) 所示,mHC 有效緩解了在HC 中觀察到的訓練不穩定問題,與基線模型相比,最終損失降低了0.021。圖5 (b) 中的梯度範數分析進一步證實了這種穩定性的提升:mHC 表現出明顯優於HC 的行為,保持了與基線模型相當的穩定輪廓。
表4:27B 模型在系統級基準測試上的結果。 本表比較了基線模型、HC 以及mHC 在8 個不同的下游基準測試中的零樣本和少樣本表現表現。結果顯示,mHC 始終優於基線模型,並在大多數基準測試中超越了HC,證明了其在大規模預訓練中的有效性。
表4 展示了在多種下游基準測試中的效能表現。 mHC 帶來了全面的提升,一致性地優於基線模型,並在大多數任務上超過了HC。值得注意的是,與HC 相比,mHC 進一步增強了模型的推理能力,在BBH 和DROP 任務上分別實現了2.1% 和2.3% 的性能增益。
規模擴展實驗
圖6:mHC 與基線模型的擴展特性比較。 (a) 計算擴展曲線:實線描繪了在不同計算預算下的效能差距。每個點代表模型大小與資料集大小的最優計算配置,涵蓋了從3B、9B 到27B 參數規模的規模擴展過程。 (b) Token 擴展曲線:展示了3B 模型在訓練過程中的軌跡。每個點代表模型在不同訓練Token 數量下的表現表現。
為了評估方法的擴展性,研究者報告了在不同規模下mHC 相對於基線模型的損失改善。在圖6 (a) 中,他們繪製了涵蓋3B、9B 和27B 參數規模的計算規模擴展曲線。其軌跡表明,即使在更高的計算預算下,性能優勢依然穩健地得以保持,僅表現出輕微的衰減。
此外,他們在圖6 (b) 中考察了訓練過程中的動態變化,展示了3B 模型的Token 擴展曲線。總的來看,這些發現驗證了mHC 在大規模場景下的有效性。這一結論在他們內部的大規模訓練實驗中得到了進一步的證實。
本文來源:機器心